

{kind=link}
{kind=link}
{kind=link}
探讨基于CitusDB的地质资料集群和大数据架构
[伍锦程 , 王占昌, 张涛]
, 王占昌, 张涛]
, 王占昌, 张涛]
|
|


第一作者简介: 伍锦程(1981—),男,工程师,主要从事地质信息服务研究。Email:46078184@qq.com。
地质资料是地质工作形成的重要成果资料,具有可被重复开发利用、能够长期提供服务的功能。然而,因地质资料的分散式管理,使得地质资料信息存储分散,“孤岛”式服务的现象普遍存在,缺乏资料信息共享、综合利用的机制和手段,制约着地质资料信息潜在价值的有效发挥。地质资料信息服务集群化旨在通过信息领域前沿技术,对地质资料进行集成集群和深度开发,将分散、孤立的地质资料进行分布式汇集,全方位多角度解读、展现、挖掘地质资料信息,充分发挥地质资料服务于经济社会发展的作用。长期的地质调查工作,已经形成了多专业、数据格式多样的海量地质资料,信息服务的集群化必将面临地质大数据相关的技术问题。介绍了地质资料信息服务集群化模式,分析了CitusDB软件的分布式大数据运行机理,探讨了基于CitusDB软件的地质资料集群和大数据服务架构,可为地质大数据与信息服务提供一定的参考。
Geological data as important information of geological work, can be repeatedly utilized and provide long-term service. But the storage of geological data is decentralized because of decentralized management of geological data, which brings about widespread islanded service. And a lack of mechanisms and methods of information sharing and comprehensive utilization restricts better utilization of geological data. Geological data are clustered and deeply developed by the cutting-edge technologies in information field. And decentralized and isolated geological data are collected spreadly, and the information are explained, revealed and excavated from different aspects. So geological data clustering information service would better serve economic and social development. However, the multi-professional, multi-formatted and massive geological data have formed in long-term geological survey work. Related technical problems of large data would occur during geological data clustering. The authors introduced the geological data clustering information service mode and analyzed the distributed data operation mechanism of CitusDB software. Geological data clustering and large data service framework based on CitusDB software were discussed. This paper would provide some reference for the large geological data and information services.
地质资料是地质工作形成的重要基础信息资源, 具有可被重复开发利用、能够长期提供服务的重要功能。新中国成立60多年来, 我国形成了海量的地质资料, 这些数据存储在全国地质资料馆、各省级地质资料馆以及各类地质工作单位和矿山企业。地质资料的分散式管理, 使得资料信息共享、综合利用的机制和手段相对缺乏, 在线服务能力相对薄弱, 制约着地质资料信息潜在价值的有效发挥。因此, 近年来中国地质调查局开展了地质大数据与信息服务工程, 隶属于该工程的西北地区地质资料信息服务集群化示范项目, 旨在通过对地质资料的集成集群和深度开发, 采用信息领域前沿技术, 疏通地质资料信息管理与服务渠道, 建立地质资料信息共享机制, 构建行业级地质资料信息服务集群化系统, 逐步消除或连通地质资料的信息孤岛。然而, 随着地质资料信息集群汇聚, 存储规模不断增大, 检索效率急剧下降, 如何将存储于数据库中的单个大表(big table)合理拆分, 将分块数据分发给多台计算机, 实现协同作业并提升效率, 需要当今前沿的分布式大数据技术为地质资料信息服务集群化提供支撑[1, 2]。从而为地质专业领域乃至社会各行各业, 提供地质资料大数据服务的新模式。
本文介绍了地质资料信息集群化服务模式, 详细分析了CitusDB软件的分布式大数据运行机理, 探讨了基于CitusDB软件的地质资料集群化和大数据服务架构, 可为地质大数据与信息服务提供一定的参考。
地质资料信息服务集群化是一项复杂而综合的系统工程, 旨在解决地质资料信息分散、综合研究力度不够、数字化信息化程度不高、服务渠道不畅及服务能力不强等诸多问题, 使地质资料信息的潜在价值得以充分发挥。从集群技术实现的角度出发, 分析地质资料信息节点群的概念及其构建要素[3]。
针对全国地质资料分布式馆藏的特点, 每个馆藏机构均能构成可独立运行的节点, 每个节点单元的各个组成要素(含数据集、运维模块等)均需具备松散耦合(弹性)特征, 每个节点围绕地质资料集群、运行环境集群和业务方法集群3方面开展常态化管理工作; 从架构体系的视角来看, 若干个节点可横向组成“ 群” 或纵向延伸成具有隶属(或嵌套)关系的“ 子群” , 每个“ 群” 具备地质资料信息发现、获取、转换、存储、同步、对等、聚合、重构和分页推送等机制。每个“ 节点群” 由门户聚合器和服务接口2部分组成, 通过数据互联互通和功能对等协同等技术, 可呈现分布式运维、协调式聚合、集群式共享(浏览器(B)-服务器(S)-节点群(N))网状或树状组网形态。
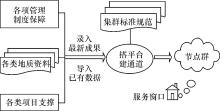
地质资料信息节点群建设需解决管理机制、信息集成和业务方法等方面的有效融合问题。地质资料信息“ 集群” 应在各项管理职能全面到位的前提下, 由地质资料汇交、管理和服务制度护航, 遵循统一的标准规范, 围绕地质资料分布式和集中式馆藏现状, 针对地质资料信息多元异构数据聚合, 以“ 节点群” 为集结单元, 通过网络共享平台面向不同的用户群体开展跨区域协同服务, 可逐步形成服务边界模糊、访问状态漂移和信息流转有序的地质资料“ 信息云” 联合体[4]。
大区与省级地质资料信息协同共享与服务机制的构成要素概括如下:
(1)制度保障。从地质资料的催交、接收、验收、保管和汇交等环节入手, 履行地质资料管理制度, 完善内部操作规程, 确保汇交质量, 为信息共享提供详实、权威的数据源。
(2)搭平台、建通道。依托信息和网络技术, 搭建分级、对等、实时、高效和智能的共享服务通道, 在保护地方权益的同时, 消除信息孤岛, 扩大地质资料信息服务的领域和范围。
(3)服务模式。在切实履行地质资料汇交制度的基础上, 通过构建集群节点体系等技术手段, 建立大区与省级之间的高效服务和对等通道, 实现地质资料信息共享发布与联动服务, 向外界呈现无缝服务窗口(图1)。
 | 图1 地质资料信息集群服务模式Fig.1 Geological data clustering information service mode |
(4)运行模式。为使大区与省级联动服务机制迈入常态化, 通过密切的业务沟通理顺各种关系, 并及时了解省级地勘工作动态和需求; 通过项目协作建立纽带关系, 加强团队技术力量聚集和人才培养。
(5)集群体系。针对馆藏地质资料集中式和分布式现状, 在面向数据资源、面向功能服务和面向业务流程的并行架构体系下, 探索地质资料信息节点集群服务模式, 实现传统的集成模式向现代的集群模式转变。
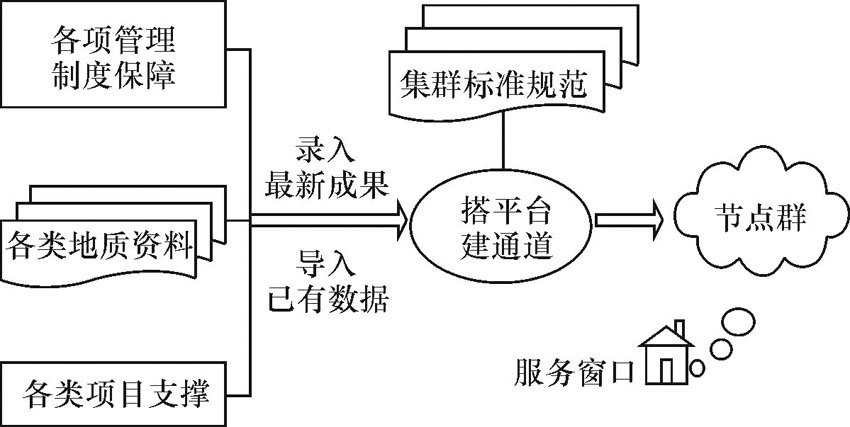
随着“ 大数据时代” 的到来, 在高并发、大数据量、分布式以及实时性的要求之下, 传统的关系型数据库, 因其数据模型及预定义的操作模式, 在很多情况下不能很好地满足上述需求。CitusDB是基于PostgreSQL数据库的“ 一主多从” 分布式大数据服务架构, 现已应用于广告技术、电子商务、零售、安全和移动分析等领域, 它的优势是将查询分布到集群中的每个节点, 快速地进行并行计算, 可以实时从数千台服务器的PB级数据中完成查询, 并支持地学空间数据的运算, 适合应用于地质大数据信息服务。CitusDB软件的运行架构如图2所示。CitusDB分布式大数据运行机理[5]详述如下。
 | 图2 CitusDB运行架构Fig.2 Operational architecture of CitusDB software |
主节点(管家)角色服务器用于存储大约几兆字节的节点群调度控制元数据信息, 同时从外部接口获取SQL查询指令, 将其重新规划形成指令片段, 并分派到各个分布式从节点上, 将各从节点执行的结果进行收割并回发至调用方, 这与大数据核心技术MapReduce过程极为类似。因此, 对该主节点服务器的性能要求不高, 存储空间也可不大, 但CPU内核数量越多越好, 这将有利于并行操作。其他服务器将用于存储实际数据并执行SQL运算任务, 充当从节点(工人)角色, 因此, 存储空间越大越好, 性能越高越好。
CitusDB采用的模块化碎块存储结构类似于Hadoop分布式系统的文件块, 区别是在从节点使用了PostgreSQL的表单, 而并非以文件的形式。这些表单就是所谓的水平分区或逻辑碎块。
当获得1条查询指令后, 主节点将该指令划分成更小的SQL语句片段, 将其分派到各个从节点, 以便每个片段可以在1个碎块上独立运行, 这种方式有效发挥了各节点的运算处理能力; 主节点把查询片段分派到从节点后, 监督其执行并将结果进行归并, 然后向调用方返回最终结果; 为确保所有查询都以1种可伸缩的方式执行, 主节点实施了优化策略, 以最大限度地减少网络传输数据量。
在CitusDB中, 被用于分布的任何表单必须具有1个可充当分布字段的“ 特殊列” 或者“ 数据项” , 依据这个特殊列值, 按确定的方式将表单进行拆解后可形成若干个数据碎块, 同时也将相应的统计信息形成元数据。CitusDB的分布式查询优化器按列的值域, 确定如何以最优的方式执行查询指令。数据库开发人员选择分布字段的原则, 通常取决于该字段是否适合作“ 关联” 的纽带或者充当“ 筛选” 的依据。针对筛选意图而言, CitusDB 采用分布字段的值域区间区分出无关的碎块, 确保利用where条件子句采用字段区间值进行约束的时候, 能够触及定位到与之对应的有效碎块; 针对关联意图来说, 若关联键与分布列一致, 将在这些碎块之间按分布列的值域区间值进行叠加匹配, 这将有助于减少多个节点碎块之间的计算工作量以及网络I/O吞吐量。
CitusDB 主要支持“ 追加” 和“ 哈希” 2种方法, 另外还提供了基于“ 区间” 分布的方式。其中, 追加式仅适用于往分布式环境按批处理方式推送数据表的场景, 如推送按时间间隔记录的序列化观测数据实例, 若按某个区间范围进行查询时, 基于追加式分布方法的执行效率会更高; 而基于哈希式分布方法更适合按单个记录往分布式数据库中进行实时插入和分析的场景, 被插入的记录包含与次序无关的分布列(如用户id码), 当插入事件发生时, CitusDB 将记录所有碎块哈希编码的最小和最大范围值。
地质资料信息为地学空间信息, 使得地质资料大数据架构有其特定的空间运算需求, 即地质大数据架构需支持键值对(json)数据类型、分布式并行查询技术、节点添加、删除和数据再均衡, 同时还需具备空间运算函数[6]。
CitusDB是在对PostgreSQL进行改写和扩充的基础上, 免费开源的分布式大数据平台, 支持键值对数据类型, 支持分布式并行查询技术, 通过碎片化分区、碎块复制和并行查询等技术, 可在多台物理机或虚拟服务器间创建具有弹性伸缩和实时响应能力强的集群服务框架。PostgreSQL是唯一一款免费开源且十分成熟的地学空间数据库管理系统, 其PostGIS扩展模块自带1 000余个空间信息处理函数, 能为PostgreSQL提供了强大的空间数据库引擎, 特别适合GIS大数据的分析和挖掘。由此可见, 基于CitusDB、PostgreSQL和PostGIS的大数据架构适合于地质资料大数据, 可为目前分散式服务的地质资料馆藏机构, 创建具有高可靠、高扩展、高效性、高容错性和低成本的地质资料信息服务大数据平台。基于CitusDB的地质资料“ 一主多从” 大数据架构如图3所示。
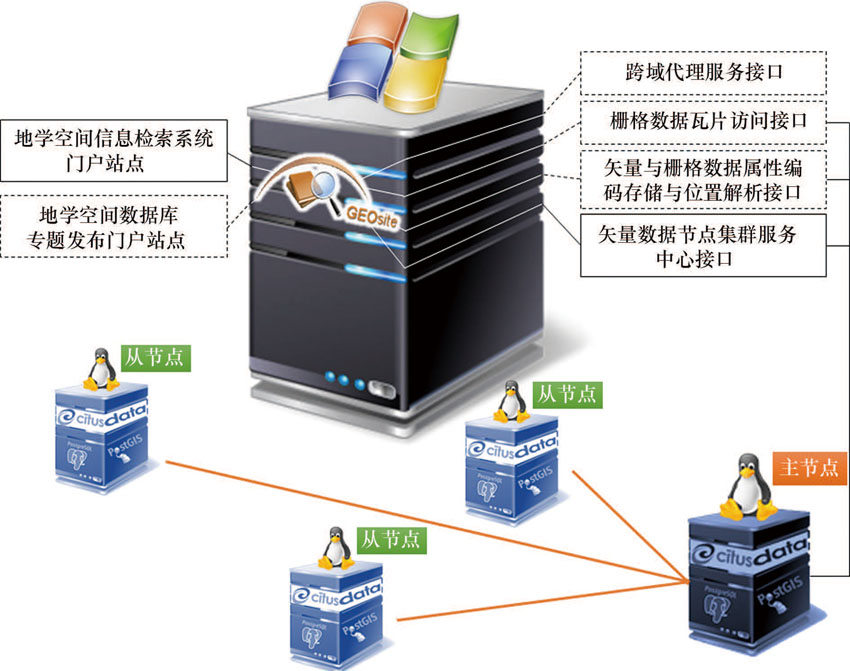 | 图3 基于CitusDB的地质资料“ 一主多从” 大数据架构Fig.3 “ One-master multi-slave” architecture of large geological data based on CitusDB software |
地质资料按地质专业可划分为区域地质调查资料、矿产勘查资料、海洋地质资料、工程地质资料、环境地质、灾害地质资料、物探、化探地质资料、石油、天然气、煤层地质资料和其他地质资料等。不同类别的原始地质资料因在数字化过程中所使用的软件不同, 会造成数据格式的多样性, 具有典型的多元异构特点[7]。构建地质资料信息大数据系统, 首先应解决多元异构数据的统一化描述, 其次是数据的分布式存储, 以及数据共享与服务。
多元异构数据的统一化描述, 可依据中国地质调查局发布的各类地学空间数据库建设指南, 并参照开放式地理信息系统协会(Open GIS Consortium, OGC)标准, 采用轻量型结构化文本语言(xml), 对地质资料数据进行统一化描述, 形成具有通用性和兼容性的数据格式。如地质资料矢量数据(地质资料目录数据库、地质工作程度数据库等), 可从空间信息中抽取共性描述特征, 将地质资料划分为“ 点、线、面” 3类要素进行xml格式的统一化描述, 并按照“ 数据仓-数据集-数据库-数据层” 4级分类体系进行有限划分和映射, 其中1个数据仓可对应多个数据集(如地质资料按地域划分), 1个数据集可对应多个数据库(如地质资料按专业分类), 1个数据库可对应多个图层(如地质资料按比例尺分级), 每个图层可同时容纳任意多个点、线、面要素, 从而形成统一的金字塔状目录结构树, 充分体现多元异构的思想。
数据的分布式存储, 在CitusDB的PostgreSQL数据库中, 创建用于分布的数据表, 并指定1个可充当分布字段的“ 特殊列” 或“ 数据项” (如id)。依据这个特殊列的值, 按“ 追加” 或“ 哈希” 的方式将表单拆解, 形成若干个数据碎块, 数据碎块分布式存入不同的数据节点。如将统一化描述后的数据(xml), 以二进制编码形式推入PostgreSQL数据库并形成分布式大数据资源池; 栅格类数据, 如卫星影像、地球物理、地球化学、水文及环境地质等值线渲染模型数据, 需进行四叉树切片, 然后将四叉树切片影像数据, 以WKB编码形式推入PostgreSQL 数据库并形成分布式大数据资源池。
数据的共享与服务[8], 首先地质资料的共享与服务需按照国家的相关保密法律, 进行严格审批, 禁止发布涉密数据, 现阶段可面向互联网服务的地质资料有地质资料目录数据库、工作程度数据库和公开发行的地质图等; 其次各馆藏机构节点应按照《推进地质资料信息服务集群化产业化工作方案的通知》(国土资发[2010]113号)精神, 遵循“ 坚持公共服务、全面覆盖、互联互通、维护权益、逐步推进、共同参与” 6项原则, 对各节点的数据进行权益维护; 最后在节点间的数据同步对等方面, 各馆藏机构的数据节点需建立对等链路, 仅允许共享数据进入对等链路, 私有数据存放在本地节点, 禁止其他节点同步对等, 数据池通过对等链路的刷新机制实现同步对等。
地质资料信息服务集群化后, 当数据量大到一台计算机无法进行存储、无法在预定时间内完成处理任务的时候, 传统的地质资料信息系统需要在数据结构(如键值对异构映射、哈希分区)、通讯机理(如池化连接、序列化并行冲突)和查询语句等进行较大程度的改造, 按分布式大数据约束条件(如必须按哈希键进行分区), 厘定字段类型, 精心编写SQL查询语句, 以便满足分布式大数据架构对数据处理语言的限制和要求。西安地质调查中心采用基于PostgreSQL的CitusDB “ 一主多从” 分布式大数据架构, 并嵌入了PostGIS空间数据库引擎, 成功搭建了具备5个节点的大数据级地学空间信息检索系统, 并通过该系统测试了1∶ 3 500万世界地质图数据库和境内非涉密1∶ 250万地质图数据库的地质体属性, 以及全球SRTM数据超过269亿个像素细粒度内容的高速解析服务, 解析时间大约0.04 s, 而用单台PostgreSQL处理这些数据需要10 s以上, 解析速度低。综上所述, 基于CitusDB的地质资料“ 一主多从” 分布式大数据架构适用于地质大数据与信息服务, 建议进一步研发适合地质专业领域的大数据分布式并行计算方法, 以便对地质大数据进行深度分析和挖掘。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|