


{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于加权信息量和加权确定性系数的藏东南滑坡易发性评价
[黄永芳 , 郭永刚
, 郭永刚* , 黄艳婷]
, 郭永刚, 黄艳婷]
|
|


第一作者简介: 黄永芳(1997—),女,研究生,主要从事西藏重大工程地质灾害监测与分析的研究工作。Email: hyf19923643751@qq.com。
藏东南地区属高原地区,山势险峻,复杂的地形地貌诱发地质灾害的发生,加大工程建设的难度。为分析研究区滑坡灾害的易发性,选取8个评价因子(与道路距离、与水系距离、高程、坡度、坡向、工程地质岩组、土壤类型、地表覆盖)为量化指标,以层次分析法确定权重值,同时借助ArcGIS得到加权信息量模型和加权确定性系数(certainty fator,CF)模型,对比选取准确度高的滑坡灾害评价模型,运用受试者特征曲线(receiver operate curve,ROC)验证结果准确性。研究结果如下: ①加权CF模型的受试者特征工作曲线下的面积(area under receiver operating characteristic curve,AUC)值高于加权信息量模型AUC值,加权CF模型结果覆盖滑坡点多于加权信息量模型,研究区滑坡易发性评价选取加权CF模型分析结果更加准确; ②加权CF模型将研究区滑坡易发性评价结果划分为高易发区、较高易发区、中高易发区、较低易发区、低易发区,其中高易发区主要分布在墨脱县和贡觉县,较高易发区分布在卡若区、芒康县,中高易发区分布在类乌齐县、丁青县、江达县,较低、低易发区分布在巴宜区和朗县等。滑坡易发区的划分可为该区域的工程建设提供决策依据。
The southestern Tibet is a plateau region with steep mountains. The complex topography and geomorphology would easily induce geological disasters and increase the difficulty of engineering construction. In order to analyze the landslide susceptibility in this area, the authors in this paper selected eight evaluation factors as quantitative indexes, including distance from road, distance from water system, elevation, slope, slope direction, engineering geological rock group, soil type, and surface cover. The weighted value was determined by analytic nierardty process, and weighted informativeness model and weighted certainty factor (CF) were obtained by ArcGIS. Finally, the receiver operate curve was adopted to verify the accuracy of the results. The research vesullts are as follows (1) The AUC value of the weighted CF model is higher than the AUC value of the weighted informative ness model, and the covered landslide points from the weighted CF model the than those from the weighted informative ness model. So, the weighted CF model is more reliable in assessment of landslide susceptibility in this area. (2) The susceptibility zone is divided into high, relatively nigh, medium-high, relatively low, and low susceptibility zones by weighted CF model. The high susceptibility zone is mainly distributed in Mutuo and Gongjue counties, and relatively high susceptibility zone is distributed in Karuo and Mangkang counties. The medium-high susceptibility zone is distributed in Qiangwuqi, Dinching, and Janda counties, and the relatively low and low susceptibility zones are distributed in Bayi and Lang counties. The delineation of landslide-prone areas could provide some decision-making basis for the engineering construction in the region.
藏东南地区位于海拔4 000 m以上的青藏高原, 以高山峡谷为主的复杂地形地貌使当地频繁发生滑坡、泥石流等地质灾害, 给居民造成了严重的影响, 其中最具代表性的是2018年10月11日在西藏境内江达县波罗乡发生的大型山体滑坡, 滑坡不仅造成了严重的经济损失, 还威胁着当地居民的生命安全。当前针对藏东南的地质灾害研究文献还较少: Wu等[1]分析了多个地质灾害类型的易发性评价、危险性评价, 研究方法基于层次分析法和模糊数学法; 黄艳婷等[2]以高程、与断层距离、坡度等评价因子基于层次分析法分析了泥石流的危险性评价; 韩磊等[3]以藏东南地区的降雨量值与时间关系构建模型, 得到每个地域引发降雨型滑坡的最大雨量阈值; 韩用顺等[4]以冰川融雪为主要影响因子, 建立证据权-投影寻踪模型研究了该区的灾害易发性。滑坡灾害的易发性分析有不同的数学分析方法, 如: 王盈等[5]运用统计分析方法针对藏东南的地形地貌灾害影响因素进行灾害点密度统计; 赵晓燕等[3, 6, 7]将随机森林(rand forest, RF)算法和信息量模型进行耦合, 对藏东南地区的工布江达县进行了模型分析和精度校验; 赵晓东等[8]、张虹等[9]、杨灿等[10]基于机器学习算法对滑坡易发性评价模型进行优化和改进; 常志璐等[11]、吴先谭等[12]、吴明堂等[13]基于斜坡单元的划分分析滑坡灾害的易发性。
当前针对高原环境的灾害研究和单一灾害研究存在研究区的选择以小区域为主、评价因子的选取类型少等问题。本文选取多个评价因子, 开展耦合定性与定量的研究方法, 研究藏东南地区的滑坡易发性, 可为高原地区的工程建设提供决策依据。
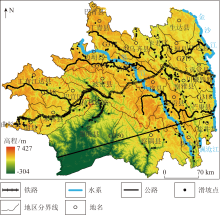
藏东南地区位于西藏自治区的东南方向, 紧邻云南、四川、青海三省, 属高原亚温带亚湿润气候。受板块抬升影响, 形成高山峡谷地势, 峡谷险峻, 其岩性以片麻岩、砂岩、千枚岩为主, 区内坡体易发生松动, 形成地质灾害。研究区内环境虽然有丰富的自然资源, 但也是地质灾害发生的典型地区, 发生次数最多的地质灾害为泥石流, 其次为滑坡。据统计数据可知, 2011— 2021年共发生257处大型滑坡。为了保证结果的精确性, 本研究统计了2011— 2021年大型、中型、小型共656处滑坡点(图1)。
 | 图1 研究区滑坡地质灾害分布图Fig.1 Schematic diagram of landslide geological hazards in the study area |
藏东南地区的地质灾害分布特征受到宏观地震地质条件的控制, 但地质灾害集群分布特征则受到多种地质、地理条件因素的影响, 包括地形地貌、地质构造、地层岩性、人类活动等[14]。本研究选取高程、坡度、坡向等影响因子作为评价因子。在使用ArcGIS处理数据前, 选取栅格30 m× 30 m的评价单元和地图矢量图作为基础条件, 分析滑坡的易发性, 如表1所示。
| 表1 滑坡灾害影响因子来源 Tab.1 Sources of landslide disaster impact factors |
滑坡易发性评价是以信息量模型和ArcGIS软件为基础, 在此基础上改进得到加权信息量模型和加权确定性系数(certainty fator, CF)模型, 对比分析两种模型选取更为准确的评价模型对研究区滑坡进行评价。
2.2.1 加权信息量模型
加权信息量模型是统计学中的层次分析模型结合信息量模型得出的新概念模型, 研究过程中选取影响因子既要考虑到因子间的作用大小, 又要考虑到因子内的影响程度, 因此需要对各个因子进行加权计算, 以提高计算结果的准确性, 该模型融合了层次模型和信息量模型的两种优点, 广泛运用在地质灾害易发性评价中[6]。
单因素信息量模型公式为
总信息量模型公式为
加权信息量模型公式为
式中: Wi为评价因子i的权重; Ij为综合所有的信息总量值; I为研究区单因子评价下的信息量值; Y为评价指标因子; Xi为函数关系中自变量; Ni为单因子i评价下的滑坡点数, 处; N为研究区单因子评价下的滑坡点总数, 处; Si为研究区包含Xi单因子评价下的栅格单元面积, km2; S为研究区单因子评价下的单元总面积, km2。
2.2.2 加权CF模型
统计学当中的CF模型是概率计算模型的一种, 该模型由Shortliffe学者在1975年首次提出, 后经过Heckerma等学者进行了优化[6]。该模型量化灾害的影响因子, 得到因子间的统计关系, 以此确定灾害事件发生的频率大小。因其模型具有高精准度、易操作等优点, 大量使用在地灾易发性评估中。模型结果由CF值确定, 当CF取值越趋于最大值1时, 表示滑坡灾害的发生可能性越高, 反之取值越低, 当取中间值时0时发生则不能确定。
加权CF模型公式
式中: CF为确定性系数; Wi为评价因子的权重; Pa为一个评价因子中的滑坡点个数与该评价因子的面积比值; Ps为研究区滑坡点总数与研究区的面积比值。
研究区地域特点为高山峡谷、水流量丰富、土地植被覆盖不均衡等, 本研究发现影响研究区滑坡灾害的因素有固体物源、地形、自然地理等因素。固体物源包括与道路距离、与水系距离, 地形因素有高程、坡度、坡向, 自然地理因素有工程地质岩组、土壤类型、地表覆盖。
(1)土壤类型。土壤类型的不同, 植被生长的类型也不同, 这在不同程度上影响着滑坡地质的发生。矢量图先通过ArcGIS软件转换为栅格数据, 最后经过重分类, 划分为娄土、黄刚土、黄堰土等6个等级(2(a))。
(2)工程地质岩组。研究区大部分为砂砾坚土, 这种砂砾土硬度介于软和强硬之间, 一旦受到高强度的应力, 坡体会发生滑动。工程地质岩组原始图层为栅格图层, 故仅需要融合操作和分级符号系统的唯一值操作, 划分为5个工程地质岩组(图2(b))。
 | 图2 研究区影响因子分级Fig.2 Impact factor classification in the study area |
(3)地表覆盖。地理位置、植被分布范围、景观布局等都在间接影响滑坡灾害的发生。地表覆盖数据分块下载后在ArcGIS软件中进行镶嵌至新栅格、按掩膜提取等操作, 分为9个等级(图2(c))。
(4)高程。滑坡灾害的发生受地形的高低影响, 为研究研究区滑坡灾害在不同高程的分布规律。首先在地理空间数据云获取原始高程数据, 然后通过ArcGIS软件进行镶嵌至新栅格、合并、按掩膜提取等操作, 最后将处理后的数据进行重分类, 选择的分区值为800, 经过自然间断法分为8个等级(图2(d))。
(5)坡度。坡度在一定范围内决定着斜坡的稳定性, 一般坡度越大, 山坡剪切力也越大, 发生滑坡灾害的概率也越大, 但坡度超过一定范围后, 滑坡的概率反而降低[15]。坡度的数据是通过ArcGIS对DEM数据的坡度处理和重分类数据值, 得到7个分级指标(图2(e))。
(6)坡向。坡向的不同, 意味着坡体结构、含水量、植被覆盖、风化程度的不同, 这些都能影响坡体的结构属性。坡向数据处理是将DEM高程数据结合ArcGIS的坡向处理进行分析, 得到坡向矢量图, 最后进行面转栅格, 得到8个分类(图2(f))。
(7)与道路距离。随着大量的道路和居民住房建设, 开挖山体, 严重影响了岩土体自身的稳定性, 导致了坡体结构应力出现失衡。本文选取的交通道路包括铁路、公路, 其中铁路有拉林铁路、川藏铁路等, 公路有国道G330、G349、G318、G317等。将道路缓冲距离作为评价因子, 考虑到研究区行政面积广, 故以800 m为分区值分为6个等级(图2(g))。
(8)与水系距离。区内有着水流量大的河流, 例如金沙江、澜沧江、怒江等。水流的冲刷改变着坡体的地质条件, 在滑坡发生时易形成堰塞湖。水系原始数据线要素包括河流、沟渠。河流选取一级、二级河流等, 详细名称为金沙江、怒江、澜沧江等。河流结构线处于分离状态需要用融合、缓冲区等操作将面要素转为栅格划分为6个等级(图2(h))。
3.2.1 确定权重
层次分析法将定性与定量相结合, 将抽象因素结合主观因素的定量评价, 按照统计学的一致性比例为标准进行检验, 使评价结果更加具有科学性。故权重是根据层次分析法得出, 分析过程如下。
(1)模型绘制。按照表1的图层分类, 层次模型的要素可分为控制目标层和控制准则层[16], 选择本文当中8个评价因子进行分层分析。
(2)判断矩阵。从层次模型图结构, 考虑各个因子间的影响关系, 按照9个标度进行专家经验的打分, 得到的矩阵数值关系。
(3)计算结果。各评价因子在矩阵中的一致性比例最小为0.017 6, λ max最大为 3.018 3, 故通过了一致性检验得出各个因子的权重值(表2)。
| 表2 层次分析法权重值 Tab.2 Weighted vallue by analytic hieratchy process |
3.2.2 加权信息量
信息量模型在层次分析法的基础上, 将主观的评价结合栅格数值得到最终结果值。先将656个滑坡点进行多值提取至点的操作, 得到各因子的栅格数量、栅格面积、栅格总面积, 然后按照式(1)和式(2)计算得到信息量值, 最后按照式(3)计算得到结果值(表3)。
| 表3 研究区评价因子分级和加权信息量值与加权CF值 Tab.3 Evaluation factor classification and weighted in formativeness values and weighted CF values in the study area |
3.2.3 加权CF值
CF模型计算值首先需要结合ArcGIS软件, 将各个评价因子图层栅格进行多值提取至点操作, 提取到各因子分级中对应位置的滑坡点数, 其次将获得的各评价因子的属性表, 按唯一值进行统计分析, 最后按照式(4)和式(5)求得加权后的CF值(表3)。
3.2.4 评价因子分级相关性分析
为验证评价因子分级是否符合统计要求, 故对不同评价因子与滑坡点分组进行相关性分析, 由不同评价因子的分级标准存在不对等, 故在SPSS软件当中, 需要先处理缺失值, 将缺失的选项用MISSing are all(999)进行填充。与道路距离、坡度、高程、与水系距离、坡向之间显著性相关, 其余评价因子之间呈弱的相关性, 说明评价因子分级标准与滑坡点个数分布符合统计要求, 也表明本文中的影响因子均可用于评价计算(表4)。
| 表4 研究区评价因子分级与滑坡点相关性分析 Tab.4 Correlation analysis between evaluation factor classification and landslide points in the study area |
在计算得到信息量值和加权CF值后, 在ArcGIS中将每个因子图层进行栅格转面, 并且在表格属性表当中添加新字段, 用于存放信息量值, 在这个过程中需要按属性查找gridcode的不同值和字段计算器中赋值添加新字段的数值。将赋值后的图层重新转为栅格进行重分类, 根据自然间断点分级法分为高易发区、较高易发区、中高易发区等, 加权CF模型下的藏东南地区滑坡高易发区主要分布在墨脱县和贡觉县, 较高易发区分布在卡若区、芒康县, 中高易发区分布在类乌齐县、丁青县、江达县, 低、较低易发区分布在巴宜区和朗县等。加权信息量模型下的藏东南地区滑坡易发区主要集中在墨脱县、波密县、察隅县, 丁青县和工布江达县靠近河流地方(图3)。
 | 图3 研究区滑坡易发性分区Fig.3 Landslide suseptibility zoning in the study area |
加权CF模型叠加的研究区分区值1.201 09~-1.563 6, 加权信息量模型叠加的分区值为1.439 04~-2.508 92。总信息量值越大, 代表越容易发生地质灾害[17]。两者对比可知, 加权CF模型高、较高、中高易发区的覆盖滑坡点为379处, 占总滑坡点的57.77%; 加权信息量模型中高、较高、中高易发区的覆盖滑坡点为162处, 占总滑坡点的24.70%, 可见加权CF模型结果相对准确(表5)。
| 表5 研究区滑坡灾害易发性分区面积统计 Tab.5 Statistics of landslide susceptibility zoning areas in the study area |
滑坡易发性评价的有效性可由受试者特征曲线(receiver operate curve, ROC)进行定量检验, 其曲线下方面积指标可用来判断模型评价结果的精度[18, 19]。ROC曲线称为感受性曲线, 是根据一系列不同决定阈, 以真阳性率(灵敏度)为纵坐标, 假阳性率(1-特异度)为横坐标绘制的曲线。受试者特征曲线检验可以检验算法是否具有可靠性。ROC结果评价取决于受试者特征工作曲线下的面积(area under receiver operating characteristic curve, AUC)大小, 曲线越靠近左上角结果越可靠。由图4可知加权CF模型的AUC值为0.908 73, 加权信息量模型的AUC值为0.727 43, AUC值越接近1, 表明精度越高, 表明采用改进的加权CF模型分析结果更加准确。
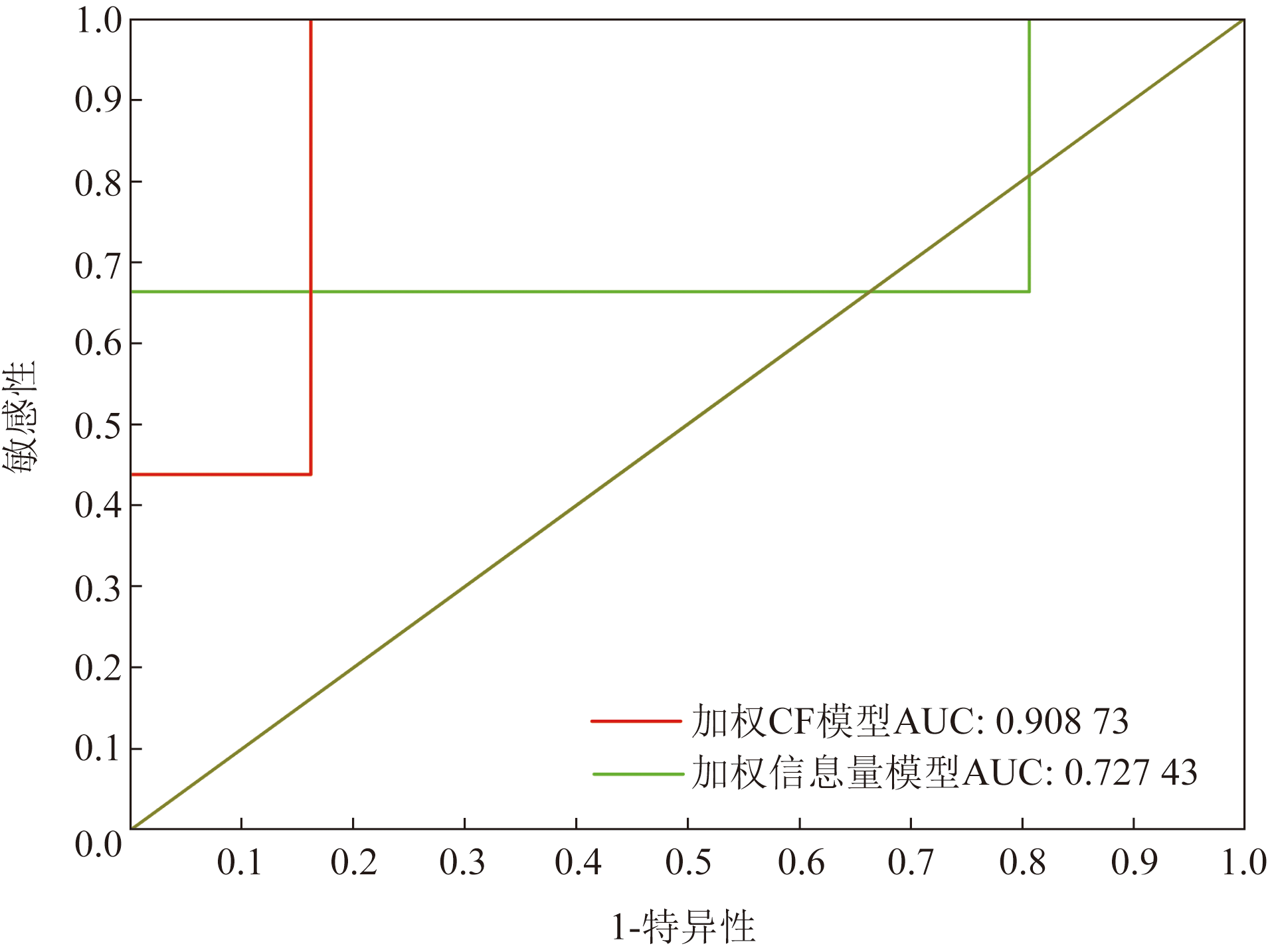 | 图4 研究区ROC曲线精度Fig.4 ROC curve accuracy in the study areaa |
(1)选取藏东南地区的8个评价因子(与道路距离、与水系距离、高程、坡度、坡向、工程地质岩组、土壤类型、地表覆盖)为量化指标, 构建加权信息量模型和加权CF模型, 运用ROC曲线验证结果准确性。加权信息量模型的AUC值为0.7274 3, 高易发区、较高易发区、中易发区覆盖滑坡点为162处; 加权CF模型的AUC值为0.908 73, 高易发区、较高易发区、中易发区的覆盖滑坡点为379处。藏东南地区滑坡滑坡评价模型选取加权CF模型结果更加准确。
(2)加权CF模型将藏东南地区滑坡滑坡易发性评价结果划分为高易发区、较高易发区、中高易发区、较低易发区、低易发区, 其中高易发区主要分布在墨脱县和贡觉县, 较高易发区分布在卡若区、芒康县, 中高易发区分布在类乌齐县、丁青县、江达县, 低、较低易发区分布在巴宜区和朗县等。
(3)本文选取藏东南地区特定的滑坡滑坡为工程建设提供参考, 但也存在不足, 例如滑坡滑坡影响因子选取类型少, 结果验证方法单一, 没有考虑滑坡灾害成链的情况。
(责任编辑: 王晗)
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|